Python Scrapy Playbook筆記
從第二課開始進行安裝與專案建立。
安裝條件 (第2課)
- python
- venv 虛擬環境
cmd
python -m venv scrapyVenv
.scrapyVenv/Scripts/activate
- scrapy
cmd
pip install scrapy
建立專案 (第3課)
使用 scrapy 創建第一個專案,使用scripy startproject project_name指令。
cmd
scripy startproject firstscraper
此時會產生一個資料夾,裡面配置文件 ( scrapy.cfg ) 及一個子資料夾 ( /firstscraper ),結構像這樣:
md
firstscraper
├── scrapy.cfg
└── firstscraper
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
firstscraper資料夾有幾個預設的內建檔案,都有相關用途,可參考 官方 文件。
釋義spider資料夾(第3課)
/spider 裡面是爬蟲程式所要放置的位置,當要擷取資料時,都須放在此處,爬蟲後的資料也會放在此處,官方 文件才有提到。
cmd
scrapy crawl books
善用scrapy shell
scrapy 提供一個爬取數據的選擇器 scrapy shell,只需要在指令後加入雙引號把爬取的網址包覆即可,網址一定要包覆在雙引號內喔!。
cmd
scrapy shell 'https://quotes.toscrape.com/page/1/'
接續就會看到選擇爬取的項目 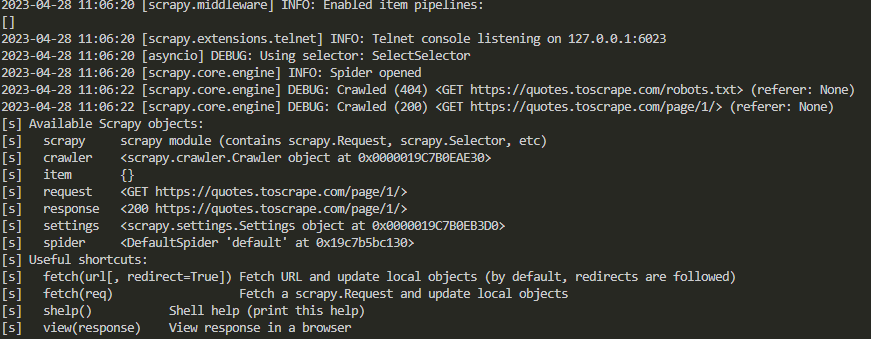 這選擇器的用意是要先查出關鍵字的位置,建議搭配瀏覽器。
這選擇器的用意是要先查出關鍵字的位置,建議搭配瀏覽器。