與資料庫對話 ( 範例 CRUD )
延續幾篇內容,以連接 mysql 直接製作常見的範例CRUD。 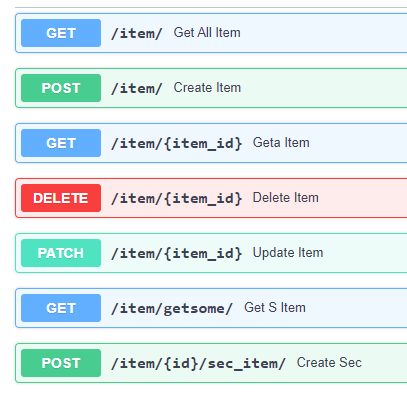
環境安裝
- venv
- FastAPI、Uvicorn、Sqlalchemy
- pymysql 或其他連接sql的模組 ( 例如 : mysql-connector-python )
TIP
如果是sqlite db不需要安裝其他模組
創建需要文件說明
前幾篇文中都一直在提到下方這兩個檔案內容周旋。
database.py連結資料庫的設定檔,有些人會把檔名命成config.py我也覺得合理。model.py資料表模組。
再來是以下這兩份文件:
schema.py共用核對欄位,查核或檢測輸入類別與資料表是否對應,欄位與model.py一樣,僅差別在宣告方式不同。crud.py處理資料表函式。
就像下方的關聯圖一樣,最終紅色箭頭的指向。 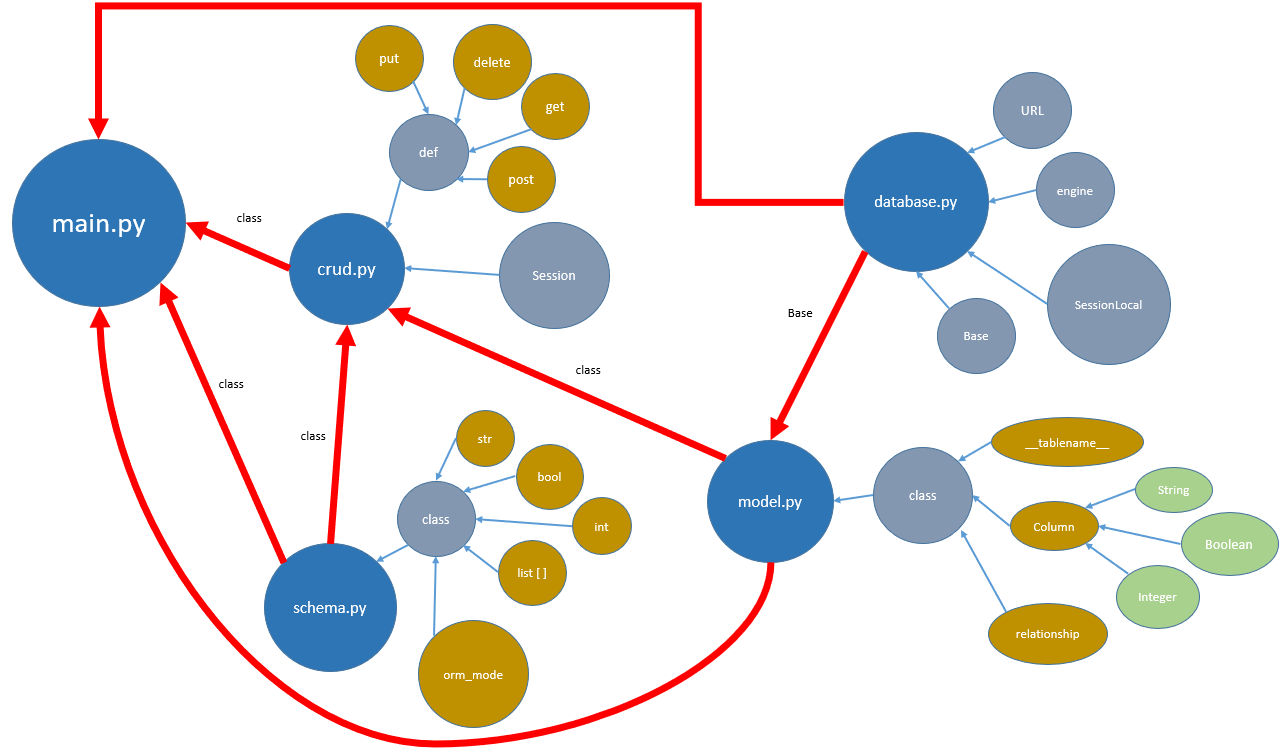
共用核對欄位 schema.py
可先參考 官方 文件。
稍微提一下class類別為何會拆分ItemBase、ItemCreate、Item三個的作用。
- 在
ItemBase類別,用在 get讀取、create創建時有共同的屬性。 - 在
ItemCreate類別,用來 create創建資料時使用,繼承 ItemBase 類別內的屬性,在 create創建資料 時,必須考量兩個 class 類別內的屬性。 - 在
Item類別,用在查詢時,就不會顯示建檔時的敏感資訊 ( 例如: password )。 Item內的Config,純粹只是要開啟 Pydantic 的 orm 模式。
py
class ItemBase(BaseModel):
email:str
title:str
class ItemCreate(ItemBase):
password:str
class Item(ItemBase):
id:int
item:list[Item]=[]
class Config:
orm_mode=True
Read 讀取 ( get )
萬事起頭get,先從讀取資料開始,順便測試能否連上資料表,一般取用資料會使用3種方法 :
- 取用全部。
- 取單筆。
- 取區間。
以下會舉例使用方法的函式。
開始建立 crud.py
先引入sqlalchemy 套件與 models、schema 設定好的資料庫內容。
- sqlalchemy.orm 是使用 orm 方法與資料庫對話。
- models 是引入資料表模組。
- schema 共同核對欄位。
py
# crud.py
from sqlalchemy.orm import Session
from models import products
import schema
py
def get_all(db:Session):
return db.query(models.products).all()
py
# 以下是定義取單筆資料使用 `id` 來篩選。
def get_one(db:Session, item_id: int):
return db.query(models.products).filter(models.products.id==item_id).first()
py
# 區間資料當然要先定義 :起始值 (`get_start`)、結束值 (`the_end`)。
def get_db_s(db:Session, start:int=0, end:int=100 ):
return db.query(models.products).offset(get_start).limit(the_end).all()
get 的總結:
- 採用 Session 來定義 db 。
- 採用 query 來取用 model 內的資料表。
- 延續2. ,採用 filter()、offset()、limit() 來篩選內容。
- 採用 first()、all() 來呈現篩選後的資料。
引到 路由 內 main.py 或 router.py
上述函式定義後,接這要引到路由才能使用。
py
from fastapi import HTTPException,Depends
from * import crud, models, schema
from database import SessionLocal, engine
開啟資料庫,讓session與資料庫對話,並確保取得資料後即關閉,避免資源消耗。這段可放在main.py或router.py內,只要有路由及取用資料庫的檔案中。
py
# 建立資料庫
models.Base.metadata.create_all(bind=engine)
py
# 取用資料庫,這裡攸關多方連線時,資料操作關閉,避免延遲。
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
TIP
py
models.Base.metadata.create_all(bind=engine)
這段是叫 sqlalchemy 檢查資料庫內有沒有 models 裡面定義的資料表,如果沒有,就會在裡面建立。 
分成3段 :
py
@app.get('/path',response_model=list[schema.get_item])
def read_all(db:Session=Depends(get_db)):
return crud.get_all ( db )
py
@app.get('/path/{id}',response_model=schema.get_item)
def read_one(id:int, db:Session=Depends(get_db)):
item_name=crud.get_one (db, item_id=id)
# 判斷id資料是否不存在
if item_name is None:
raise HTTPException(status_code=404, detail=f"Not Found id:{id}")
return item_name
py
@app.get('/path',response_model=list[schema.get_item])
def read_db_s (get_start:int=0, the_end:int=100, db:Session=Depends(get_db)):
return crud.get_db_s (db, start=get_start , end=the_end)
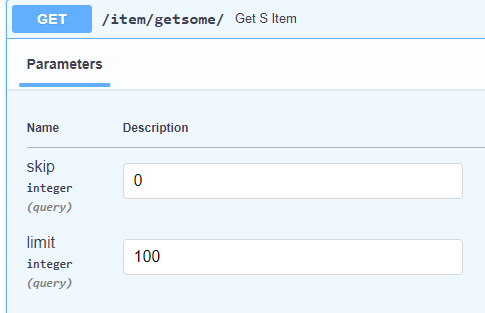
路由總結
- @app.get ('路由',response_model=清單 [ schema 自定義項目])
- def 定義方法 ( 篩選值 , 資料庫名 )。
- 篩選資料庫內容 : 定義操作.操作方法 ( 資料庫, 篩選值 )。
- 使用判斷資料正確性。
- return 回饋篩選後的內容。
提醒
建立路由,這裡兩個路由差異在於 { id }、 list 參數,雖然都是使用相同的 schema define,在 CRUD 的方法中都會用到,要記住。
py
# 多項數據
@app.get('/path',response_model=list[schema.def])
# 單項數據 (指定id)
@app.get('/path/{id}',response_model=schema.def)